OmniPredict AI can help cars accurately predict pedestrian behaviors
New AI from Texas A&M and KAIST predicts pedestrian actions in real time, offering a safer future for autonomous vehicles.

 Edited By: Joseph Shavit
Edited By: Joseph Shavit
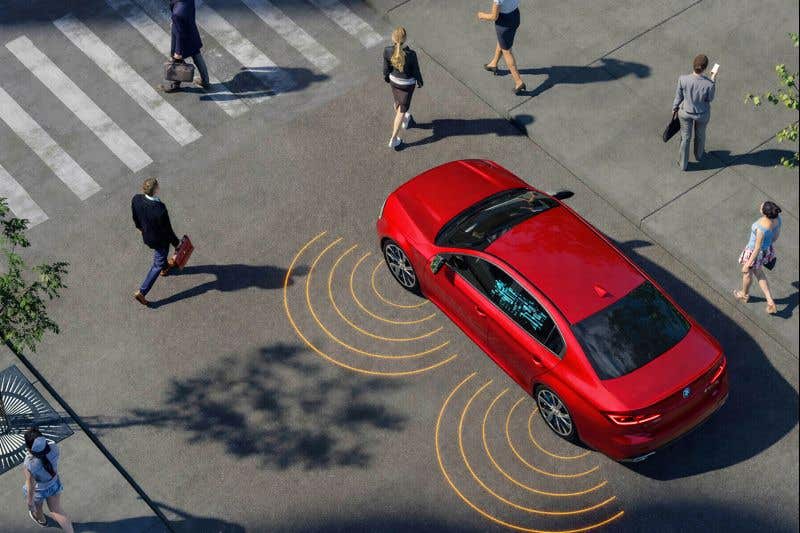
Researchers developed an AI system that anticipates pedestrian behavior before it happens. (CREDIT: AI-generated image / The Brighter Side of News)
You are standing at a busy intersection. A car slows as you approach the curb. No driver looks back at you. Instead, software inside the vehicle is deciding what you are about to do next.
That moment captures the goal behind a new artificial intelligence system called OmniPredict, developed by researchers at Texas A&M University’s College of Engineering and the Korea Advanced Institute of Science and Technology. The work is led by Dr. Srinkanth Saripalli, director of the Center for Autonomous Vehicles and Sensor Systems at Texas A&M. Their study explores how machines can move beyond simply detecting pedestrians to predicting their behavior before it happens.
The findings, published in the journal Computers & Engineering, describe one of the first efforts to use a multimodal large language model to forecast pedestrian actions in real time. The same family of AI systems that power advanced chatbots now aims to make streets safer.
“Cities are unpredictable. Pedestrians can be unpredictable,” Saripalli said. “Our new model is a glimpse into a future where machines don’t just see what’s happening, they anticipate what humans are likely to do, too.”
From Reaction to Anticipation on City Streets
Pedestrians remain the most vulnerable people on the road. Unlike drivers, they have no physical protection. For autonomous vehicles, predicting whether someone will cross the street can determine whether a car slows down, stops, or continues moving.
Earlier systems focused on reaction. Cameras detected a person. Algorithms tracked motion. Vehicles responded after movement began. Those approaches work in familiar conditions, but they often fail when weather shifts, lighting changes, or people behave in unexpected ways.
OmniPredict takes a different path. Instead of reacting to movement alone, it tries to understand intent.
“It opens the doors for safer autonomous vehicle operation, fewer pedestrian-related incidents and a shift from reacting to proactively preventing danger,” Saripalli said.
That shift changes how streets may feel. At a crosswalk, there is no eye contact or hand signal. The vehicle quietly plans around your next likely move.
“Fewer tense standoffs. Fewer near-misses,” Saripalli said. “Streets might even flow more freely. All because vehicles understand not only motion, but most importantly, motives.”
How OmniPredict Reads Human Behavior
OmniPredict is built on GPT-4o, a multimodal large language model designed to reason across images, text, and structured data. Instead of generating conversation, the model interprets scenes and predicts behavior.
The system uses four inputs. It analyzes a wide scene image to understand the environment. It studies a close-up image of the pedestrian. It reads bounding box data that describes position and size. It also factors in the speed of the vehicle itself.
Sixteen past video frames feed into the system. OmniPredict then predicts what will happen about one second later.
Researchers asked the model to identify four specific behaviors. Will the pedestrian cross or not? Is the person walking or standing? Is the pedestrian partially hidden? Is the person looking toward the vehicle?
To make this work, spatial information was converted into text so the model could reason about it the same way it processes written instructions. Clear prompts forced the system to return structured answers rather than open-ended explanations.
Unlike older neural networks that rely on memory states, the model evaluates all inputs together. Attention mechanisms allow it to weigh subtle cues, such as hesitation or a change in body orientation, before reaching a conclusion.
Testing Against the Toughest Benchmarks
The team evaluated OmniPredict using two widely respected datasets in pedestrian behavior research: JAAD and WiDEVIEW.
"JAAD contains more than 82,000 annotated frames showing pedestrians in varied traffic conditions. WiDEVIEW was recorded on a university campus and includes daytime and late-afternoon scenes," Saripalli shared with The Brighter Side of News.
"Without any task-specific training, OmniPredict reached 67 percent accuracy when predicting whether a pedestrian would cross the street. That result exceeded existing models by about 10 percent. The system also achieved the highest area-under-the-curve score among all models tested," he continued.
Notably, some supervised systems trained on large datasets recorded higher detection rates. However, those systems required extensive training and fine-tuning. OmniPredict matched or surpassed their accuracy without that overhead.
“It even maintained performance when we added contextual information, like partially hidden pedestrians or people looking toward a vehicle,” Saripalli said.
The model also responded faster and generalized better across different road settings, which are essential traits for real-world deployment.
What the Model Gets Right, and Where It Struggles
Performance depended strongly on how visible a pedestrian was. Smaller figures in the frame reduced accuracy because less visual detail was available. As pedestrians occupied more of the image, predictions improved.
Ablation tests revealed what mattered most. Removing the global scene image caused the largest drop in performance. Eliminating bounding box data or vehicle speed also reduced accuracy. The findings suggest that understanding the full environment matters as much as tracking a person.
In challenging scenes with snow, wet pavement, or multiple pedestrians, OmniPredict often succeeded where other models failed. It picked up on head orientation and early movement cues that signaled intent.
Still, the system is not perfect. Heavy shadows, severe occlusion, or cyclists sometimes led to incorrect predictions. The researchers note that separating pedestrians from similar road users remains difficult without explicit labeling.
Beyond Crosswalks and Traffic Lights
While road safety drove the research, the implications extend further.
“We are opening the door for exciting applications,” Saripalli said. “For instance, the possibility of a machine to capably detect, recognize and predict outcomes of a person displaying threatening cues could have important implications.”
In military or emergency settings, the ability to read posture, stress signals, or hesitation could offer earlier warnings and better situational awareness.
“Our goal in the project isn’t to replace humans, but to help augment them with a smarter partner,” Saripalli said.
The study also highlights transparency. When asked to explain its decisions, OmniPredict often provided clear reasoning tied to movement patterns and environmental context. That interpretability is critical for trust in safety-focused AI systems.
Practical Implications of the Research
The findings suggest a shift in how machines interact with people in shared spaces. By predicting behavior rather than reacting to it, autonomous systems may reduce accidents and improve traffic flow. For researchers, the work shows that general-purpose multimodal models can rival specialized systems without costly training.
In the future, this approach could lower barriers for deploying advanced safety tools across different cities and environments. It may also influence how AI systems assist humans in high-risk settings, from disaster response to security operations. By blending perception with reasoning, the research points toward machines that adapt more naturally to human behavior.
Research findings are available online in the journal Computers & Electrical Engineering.
Related Stories
- Groundbreaking new AI can help prevent car crashes before they happen
- Advanced driving assistance systems can do more harm than good, study finds
- New AI systems are teaching machines to verifiably function safely
Like these kind of feel good stories? Get The Brighter Side of News' newsletter.
Shy Cohen
Writer


