New AI tool revolutionizes the way scientists diagnose and treat diseases tied to protein clumping
A new AI model called CANYA helps explain why proteins form sticky clumps, with major impacts for medicine and biotechnology.
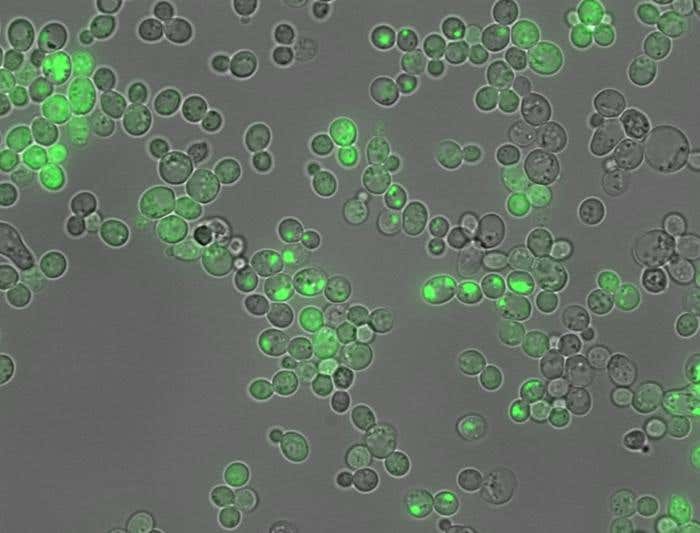
New AI tool CANYA helps scientists decode protein clumping, advancing treatment for diseases like Alzheimer’s and drug development. (CREDIT: Benedetta Bolognesi/IBEC)
A new AI tool called CANYA may change the way scientists understand and treat over 50 diseases tied to protein clumping, including Alzheimer’s. Created by researchers from the Centre for Genomic Regulation and the Institute for Bioengineering of Catalonia, this model helps decode the chemical language that drives harmful protein aggregation. For the first time, scientists can not only predict when proteins will form sticky clumps but also explain why.
Proteins sometimes clump together in harmful ways, forming sticky structures called amyloid fibrils. These clumps disrupt healthy cell function and are at the heart of many diseases, including some of the most common forms of dementia. Over half a billion people worldwide are affected. Amyloids don’t just appear in humans either; they exist in all forms of life. Sometimes they serve useful roles, but often they spell trouble.
CANYA represents a major shift from typical AI models used in biology. Most AI tools operate like black boxes, giving results without showing how they got there. But CANYA was designed to explain its decisions, offering insights into the rules proteins follow when they clump. And it does so with more accuracy than other models—about 15% better, in fact.
Training CANYA: A Massive Experiment
The tool's power comes from the biggest dataset ever made for studying protein clumping. Scientists created more than 100,000 synthetic protein fragments, each 20 amino acids long. These fragments were tested in yeast cells. When a fragment caused clumping, it changed how the yeast grew. This gave scientists a simple way to spot which fragments were the problem.
Out of 100,000 fragments, about 22,000 caused clumping. This number is thousands of times larger than what past research could study. "We created truly random protein fragments, many of which don’t even exist in nature," said Dr. Mike Thompson, the study’s lead author. "Evolution only explores a tiny piece of what’s possible. We explored a much bigger space, helping us find general rules."
With this enormous dataset, the team trained CANYA to spot patterns. The model combines two types of AI. First, a convolution layer scans the protein like facial recognition software scans images for features. It looks for short amino acid patterns—like "motifs"—linked to clumping. Then an attention layer helps the AI figure out which of these motifs really matter in the full protein.
Related Stories
- Breakthrough new protein could help people live longer and stay healthier
- Powerful new protein effectively delivers cancer-fighting drugs directly into cells
- Scientists discover natural antibiotics hidden within human proteins
This hybrid design allows CANYA to zoom in on specific patterns while also seeing their bigger role. As a result, it not only predicts if a fragment will clump, but also highlights why certain motifs matter more than others. For example, it discovered that water-repelling amino acids tend to spark clumping, especially when located near the start of the protein.
What Makes Proteins Clump?
CANYA confirmed several known facts. For instance, amyloid fibrils often form from proteins with hydrophobic (water-repelling) cores and beta-sheet structures. But it also uncovered new rules. Some amino acids thought to prevent clumping can, in certain combinations, promote it instead. And where a motif appears in the protein chain—start, middle, or end—can make a big difference.
This helps explain why earlier methods fell short. Many older tools focused on just a few properties like hydrophobicity. They also relied on small and often biased datasets, which made their predictions unreliable. When tested against the new massive dataset, those models had only modest success.
The field has struggled with this for years. Even though the atomic structures of mature amyloid fibrils have been mapped, how and why clumping begins remains unclear. Most proteins don’t naturally form amyloids. There’s a high energy barrier to starting the process. Scientists believe this step is controlled more by timing and sequence features than anything else.
The randomness of the new dataset offers a powerful way to spot what truly matters. By capturing many sequences that evolution never explored, the study shows which rules are general and which are just exceptions. Even small differences in amino acid placement can turn a harmless sequence into a disease-causing one.
Impacts on Medicine and Biotech
While the results could help in studying diseases like Alzheimer’s, their biggest impact right now might be in biotech. Many drugs are made from proteins. If those proteins clump, entire batches can fail. That’s both costly and time-consuming.
"Protein aggregation is a major headache for pharmaceutical companies," says Dr. Benedetta Bolognesi. She led the work at IBEC. "If a protein clumps, the whole manufacturing process can fall apart. CANYA can help us design drugs that don’t stick together, saving time and money."
And that’s not all. The researchers plan to improve the model. Right now, it only tells whether a sequence will clump or not. The next goal is to predict how fast aggregation will happen. That timing is vital for diseases where early clump formation leads to faster decline.
"There are 10^24 different ways to build a 20-amino acid sequence," Bolognesi explains. "We’ve only studied 100,000 so far. But our work shows it’s possible to start making sense of this huge space."
Their approach is also cost-effective. By using DNA synthesis and sequencing, thousands of protein sequences can be tested in a single tube. This saves money while generating vast amounts of useful data. "We’re applying this same method to other tough biology problems," adds Professor Ben Lehner. "The goal is to make biology something you can predict and program."
Toward Predictable Biology
CANYA stands out not just because it performs better, but because it explains itself. This makes it useful for other scientists who want to tweak protein designs or understand disease mechanics. It works like a translator, turning the language of proteins into something we can read and act on.
The project shows what’s possible when large-scale experiments meet smart machine learning. Instead of guessing how proteins behave, we can begin to know. That knowledge opens the door to better treatments, safer drugs, and a deeper understanding of life itself.
This study was supported by the European Research Council, the Spanish Ministry of Science, and other international research grants. It represents collaboration between several leading institutions, including the CRG, IBEC, Cold Spring Harbor Laboratory, and the Wellcome Sanger Institute. The full findings were published in Science Advances.
Note: The article above provided above by The Brighter Side of News.
Like these kind of feel good stories? Get The Brighter Side of News' newsletter.